Publications
* denotes equal contribution.
2026
-
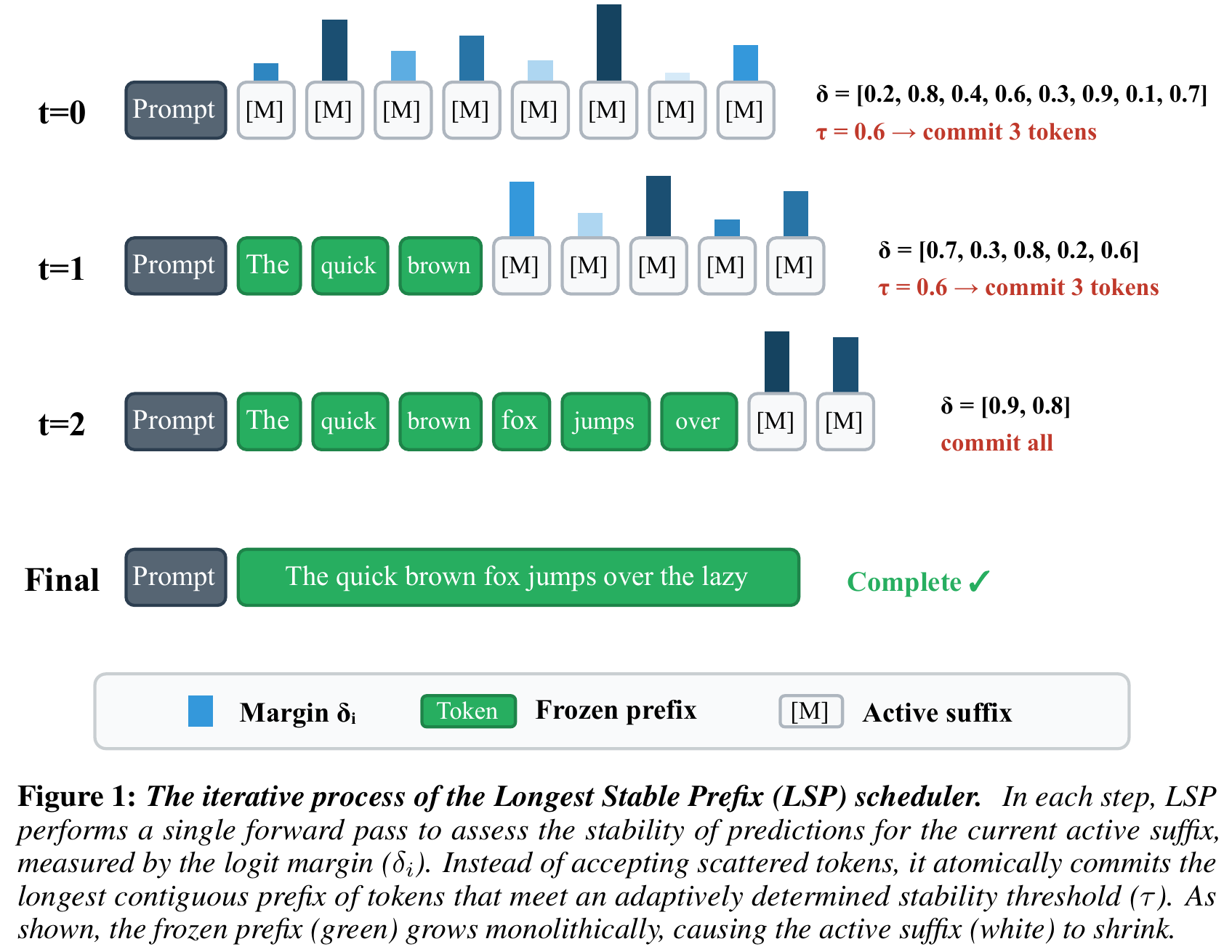 Beyond Scattered Acceptance: Fast and Coherent Inference for DLMs via Longest Stable PrefixesIn International Conference on Learning Representations (ICLR) , 2026
Beyond Scattered Acceptance: Fast and Coherent Inference for DLMs via Longest Stable PrefixesIn International Conference on Learning Representations (ICLR) , 2026 -
 SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMsarXiv preprint arXiv:2602.06040, 2026
SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMsarXiv preprint arXiv:2602.06040, 2026


2025
-
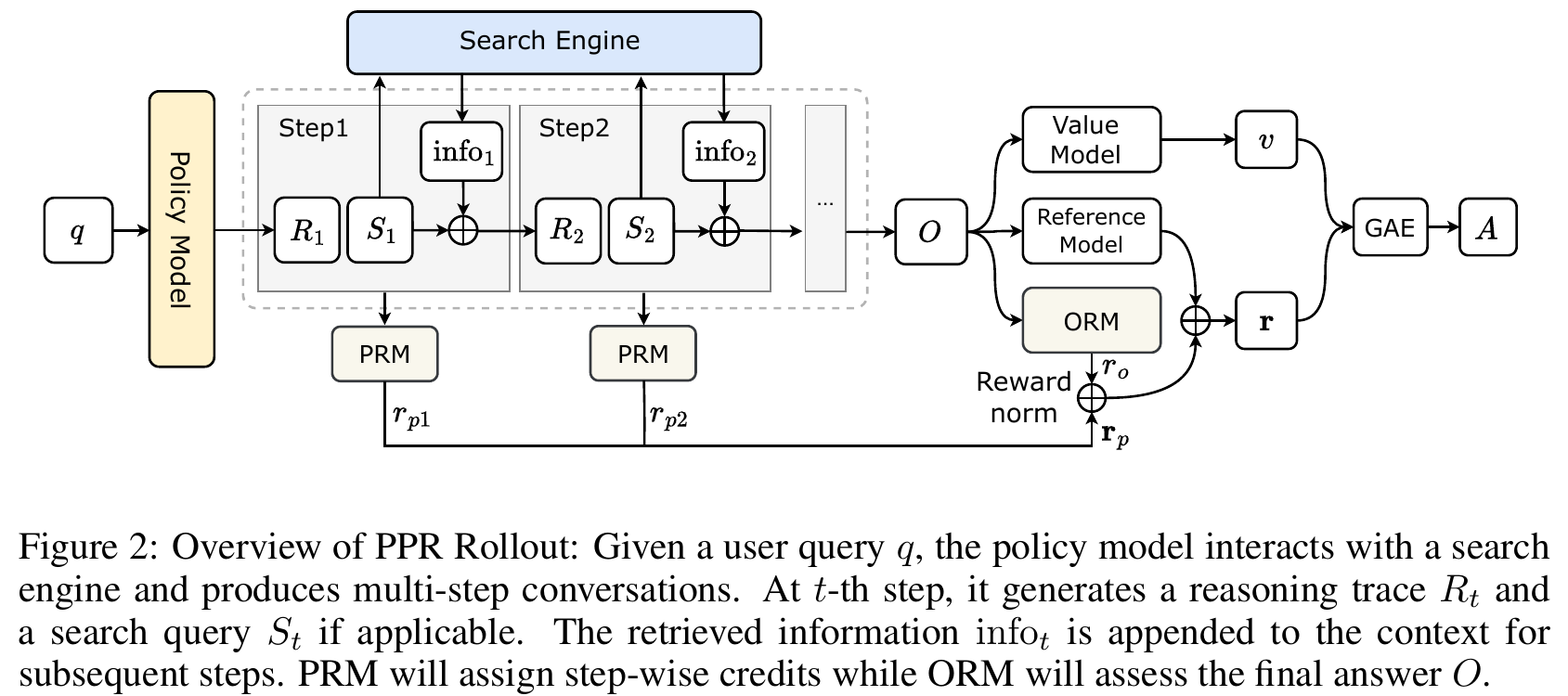 Hybrid Reward Normalization for Process-Supervised Non-Verifiable Agentic TasksarXiv preprint arXiv:2509.25598, 2025
Hybrid Reward Normalization for Process-Supervised Non-Verifiable Agentic TasksarXiv preprint arXiv:2509.25598, 2025

2024
-
 Enhancing Vision-Language Pre-training with Rich SupervisionsIn Computer Vision and Pattern Recognition (CVPR) , 2024
Enhancing Vision-Language Pre-training with Rich SupervisionsIn Computer Vision and Pattern Recognition (CVPR) , 2024


2023
-
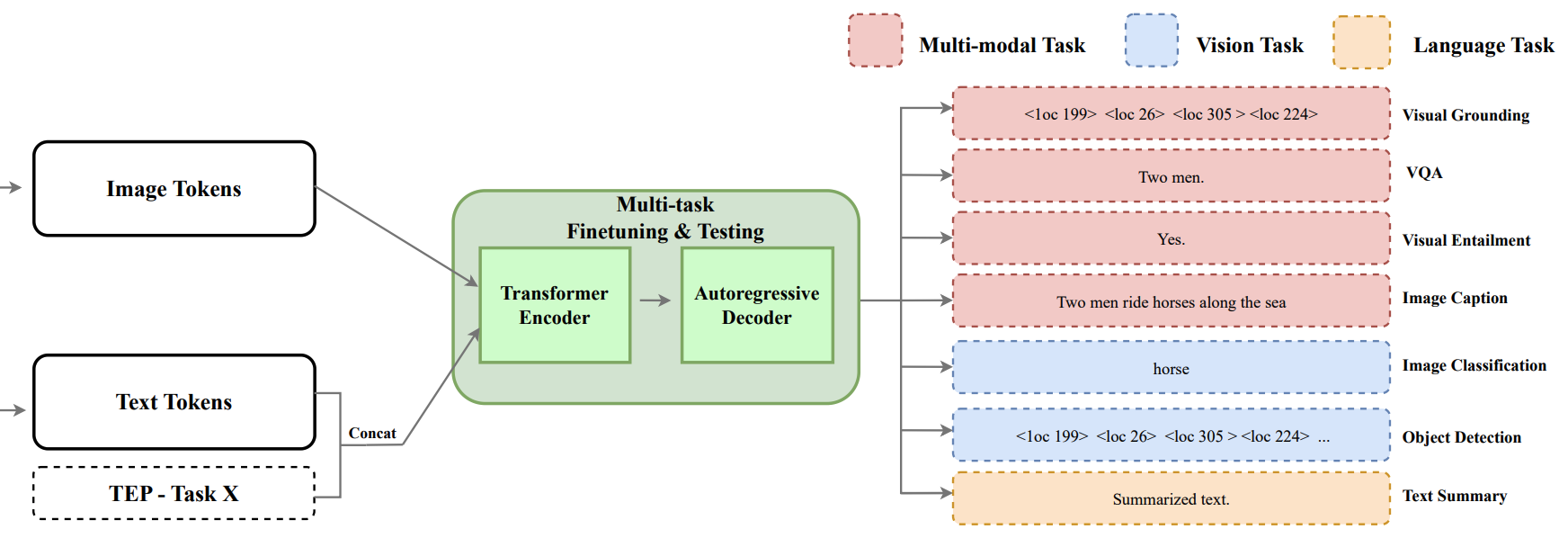 Musketeer (All for One, and One for All): A Generalist Vision-Language Model with Task Explanation PromptsarXiv preprint arXiv:2305.07019, 2023
Musketeer (All for One, and One for All): A Generalist Vision-Language Model with Task Explanation PromptsarXiv preprint arXiv:2305.07019, 2023

